
Und wieder einmal hat sich der November nicht als idealer Zeitpunkt für ein Hybridevent herausgestellt. Wenn Sie wissen wollen was daraus geworden ist, lesen Sie hier weiter:
KI mit Köpfchen, Strategie als Erfolgsfaktor…
Unter diesem Motto haben wir am 30. November 2021 aufgezeigt warum es wichtig ist nicht nur ein paar Data Scientisten/Innen für Datenbereinigung und Programmierung abzustellen. Wenn das Management nicht mit einer Strategie dahinter steht, wird es kein erfolgreiches Data Science Projekt geben. Unser Kollege und Senior Data Scientist, Ingo Nader, hat mit seinem Vortrag „Rocky Horror Data Show“ das KI-Gruselkabinett dem AI-Wunderland gegenübergestellt und dabei die goldene Mitte aufgezeigt, wie es im realen Business laufen kann, soll und warum. Unser Gastredner, Thomas Huber, CEO unseres Partnerunternehmens mosaiic GmbH, hat aus seiner Sicht als Unternehmensberater in Deutschland veranschaulicht, warum ein KI (Künstliche Intelligenz)-Projekt nur erfolgreich sein kann, wenn das Management die entsprechende Priorität dazu setzt. Und auch aus Managementsicht wurde berichtet: Rainer Kegel, CIO der Wiener Stadtwerke, hat gezeigt wie im öffentlichen Dienst erfolgreich AI (Artificial Intelligence)-Projekte gemacht werden.
Am Tag des Events lief alles reibungslos über die Bühne. Aber bis dahin gab es einen kleinen Umweg…
Der Start
Im September begannen die Vorbereitungen: Terminfindung mit Podiumsgästen, Definition des Inhalts und Absprache mit den Gastvortragenden, Aktivierung der Dienstleister für Grafik, Technik, Texte, LinkedIn Kampagne, Toolaccounts, und und und. Als „Studio“ wurde schnell unser Büro auserkoren und schließlich hat sich der Termin 30. November heraus kristallisiert.
Die Umleitung
Doch dann kamen die Corona-Maßnahmen: Am 22. November fiel die Entscheidung von Hybridevent auf reine Onlinevariante umzustellen. Auf einen Schlag fiel das Profi-Technikteam weg: alle Vorbereitungen für die Kamera-, Licht- und Tontechnik, Regieplatz und Streaming lösten sich in Luft auf. Eine Absage oder Verschiebung kam für uns nicht in Frage. Also hieß es Ärmel hochkrempeln und Vollgas geben und dabei hat das ganze IT-PS Team zusammengeholfen um das Stattfinden des Events erfolgreich umzusetzen. Danke allen Kollegen an dieser Stelle!

Übrigens: Kennen Sie unser Team schon? IT-PS Teamseite
Das Event
Die Agenda
14:00 Welcome
Werner Höger, CEO der IT Power Services
14:10Vortrag: The Rocky Horror Data Show: Mit Köpfchen aus dem Gruselkabinett
Vortragender: Ingo Nader, Data Scientist, IT Power Services
14:45Vortrag: Data Driven! … aber wohin? – Die strategische Rolle des Managements
Vortragender: Thomas Huber, Geschäftsführer, mosaiic
15:15Vortrag: Wiener Stadtwerke Data Science 360°
Vortragender: Rainer Kegel, CIO, Wiener Stadtwerke
15:45Pause
15:55Podiumstalk
Spannender Talk mit unseren Podiumsgästen
17:00virtuelles Get-Together in der IT-PS Lounge
Netzwerken virtuell und trotzdem mit persönlichem Kontakt via Webcam und Mikro – in gathertown.
19:00Sperrstunde in der IT-PS Lounge
Die Mitwirkenden

Catherine Oborny, Moderation
Catherine Oborny ist Schauspielerin, Ballerina und Moderatorin. Sie absolvierte 2002 die Schauspielausbildung am Konservatorium Wien sowie 1986-1997 eine Ballett Ausbildung an der Wiener Staatsoper bei Michael Birkmeyer. Heute fokussiert sich die Mutter zweier Kinder auf die Moderation und das Schauspiel.

Werner Höger, CEO, IT-Power Services GmbH
Werner Höger ist seit 2016 geschäftsführender Gesellschafter der IT-Power Services GmbH. Mit seiner jahrelangen Erfahrung im IT Umfeld, begleitet er mit seinen hochqualifizierten IT-PS-BeraterInnen und ArchitektInnen, Unternehmen bei komplexen IT-Projekten – von der Strategie über das Projektmanagement, der Umsetzung, bis hin zum Betrieb. Er beschäftigt sich seit vielen Jahren intensiv mit der Digitalisierung von Geschäftsabläufen im Kontext mit einer modernen IT.

Ingo Nader, Senior Data Scientist, IT-Power Services GmbH
Ingo Nader arbeitet als Senior Data Scientist für die IT-Power Services GmbH. Im Rahmen dieser und auch früherer Tätigkeiten führte und führt er verschiedenste nationale und internationale Projekte im Bereich Artificial Intelligence, Machine Learning und Data Science durch und arbeitet dabei eng mit Kunden aus diversen Branchen zusammen, um datengetriebene Use Cases zu identifizieren und umzusetzen.

Thomas Huber, CEO, mosaiic GmbH
Thomas Huber ist Geschäftsführer der mosaiic GmbH, ein Partnerunternehmen der IT-PS, und beschäftigt sich seit über 20 Jahren mit der ganzheitlichen Leistungssteigerung von Unternehmen und Unternehmensbereichen. Seine Erfahrungen in mittlerweile mehr als 100 Kundenprojekten gehen über die Bereiche der Strategie-, Organisations-, Prozess- und Digitalisierungsberatung. Dabei war der Fokus stets auf dem Zusammenspiel von Mensch, Organisation und Technik.

Rainer Kegel, CIO, Wiener Stadtwerke GmbH
Rainer Kegel (41) leitet als CIO die Strategische IT der Wiener Stadtwerke Gruppe und verantwortet die großen konzernübergreifenden IT-Projekte des Konzerns. Der studierte Betriebswirt arbeitete am Institut für Management Information Systems der WU Wien, wo er auch promovierte. Nach dem Studium wechselte Kegel in die IT von zuerst Wienstrom, dann Wien Energie. Seit Mai 2015 ist der verheiratete Vater zweier Kinder CIO der Wiener Stadtwerke.
Foto: © Wiener Stadtwerke

Patricia Neumann, Vice President, Data, AI und Automation Sales, IBM EMEA
Patricia Neumann ist 2017 als Generaldirektorin von IBM Österreich angetreten, um dem Thema Digitalisierung einen ordentlichen Boost zu verpassen. Sie ist Präsidentin der Internetoffensive Österreich, Vizepräsidentin der Industriellenvereinigung Wien und Vorstand der American Chamber of Commerce in Austria. Seit Oktober 2021 ist sie als Vice President für Data, AI und Automation Sales für IBM EMEA zuständig.

Martin Szelgrad, Chefredakteur, Report Verlag
Martin Szelgrad ist Wirtschaftsjournalist und Chefredakteur der Fachmagazine „Telekom & IT Report“ und „Energie Report“. Er ist ständiger Autor im Wirtschaftsmagazin „Report (+) Plus“, Veranstalter des IT-Wirtschaftspreises „eAward“ und Moderator.
Foto: © Adrian Almasan – www.adrianalmasan.com

Marian Schwinner, Head of Analytics, Billa Digital
Marian leitet seit 2019 den Bereich Analytics bei BILLA Digital. Gemeinsam mit seinem Team ist Marian für die Digitalisierung des Lebensmittelhändlers verantwortlich mit Fokus auf e-Commerce und digitale Services. Sein Verantwortungsbereich umfasst u.a. Data Infrastruktur, Business Intelligence und Machine Learning. Neben seinem beruflichen Tätigkeiten ist Marian sportbegeistert und gibt gern mal zu viel Geld für gutes Essen aus.
Q&A zum Nachlesen
Leider war es uns aus Zeitgründen nicht möglich alle gestellten Fragen aus dem Publikum live zu beantworten. Wir wollen Ihnen jedoch die Antworten nicht unterschlagen und haben alle Beteiligten nachträglich um die Beantwortung gebeten. Hier können Sie die Fragen sowie Antworten nachlesen:
Fragen an Ingo Nader
- Frage: „In den Projekten, die Sie bisher durchgeführt haben, wie viel Prozent ist Alptraum, wie viel Prozent ist AI Wunderland?“
Antwort: Es gibt immer beides. Natürlich ist es durchaus so, dass für viele Unternehmen AI Projekte noch nicht zum Alltag gehörten, das wäre ja am Beginn der AI Reise auch vermessen zu erwarten. Viele Unternehmen kennen da ihre Hausaufgaben noch gar nicht, insofern können sie auch noch nicht gemacht sein. Aber genau dazu können erste Projekte dienen: Erfahrung sammeln mit AI und erkennen, welche Hausaufgaben überhaupt zu machen sind. Das Wunderland spielt sich dabei oft “im Kleinen” ab, wenn beispielsweise motivierte Mitarbeiter*innen im Projekt dabei sind, die sich über Gebühr engagieren, oder wenn Stolpersteine gemeinsam vom Projektteam gemeistert werden. Das sind dann Projekte, an die man sich gerne erinnert.
- Frage: Sie haben im Vortrag einen “Data Catalogue” erwähnt. Ist der Voraussetzung, um AI Projekte durchführen zu können?
Antwort: Der Data Catalogue wurde im AI Wunderland gesichtet (zumindest in meiner Präsentation). Und nein, er ist dezidiert keine Voraussetzung, ein AI Projekt durchführen zu können. So etwas gehört zu den Hausaufgaben, auf die man stößt während man ein AI Projekt durchführt. Diese Hausaufgaben müssen (und können oft) noch nicht erledigt sein, bevor das Projekt startet. Im Projekt gibt es meist unvollständige und/oder veraltete Spaltenbeschreibungen, die oft nicht sehr aussagekräftig sind. Die nötigen Informationen über die Daten bekommt man meist dadurch, dass die Personen mit dem Wissen über die Daten involviert werden. Besonders in der Phase der Datenexploration wird dann ausgiebig diskutiert. Dieses Wissen, das dabei zu Tage tritt, ist für uns Data Scientists* unentbehrlich, aber für das Unternehmen, dem die Daten gehören, ist es sogar noch wertvoller. Auf lange Sicht – also strategisch gedacht – macht es da natürlich Sinn, dieses Wissen standardisiert zu erfassen und zugänglich zu machen, damit das Unternehmen weiteren Nutzen daraus ziehen kann. - Frage: „Es gibt eine super Weiterbildung vom WIFI –> “KI-Manager” –> gut für’s Grundverständnis.“
Antwort: Vielen Dank für den Hinweis auf diesen Kurs, der war mir noch nicht bekannt. Unser neu entwickelter Tages-Workshop “Strategie-Workshop Data & AI”, den wir mit unserem Partner mosaiic GmbH entwickelt haben, ist auf ein ganz ähnliches Ziel ausgerichtet, wenn auch deutlich konziser vom Zeitaufwand her. Der Workshop will aufzeigen, was aus Management-Sicht wichtig ist, damit Data- und AI-Projekte erfolgreich durchgeführt werden können.
Aus unserer Sicht sollte eine solche Beschäftigung mit AI auf Management-Ebene Hand-in-Hand gehen mit der Durchführung von ersten AI Projekten. Denn bei solchen Projekten wird oft erst greifbar, was AI konkret bedeutet für das eigene Unternehmen, und wie man mit solchen Projekten aus Management-Sicht umgehen kann, und wie man am besten davon profitiert.
Entsprechend kann man, wenn man schon Mitarbeiter hat, die sich in diese Richtung bewegen wollen, diese auch aktiv im Projekt einbinden. Genau daran ist auch unser IT-PS Projektmodell orientiert, in dem eine enge Abstimmung aller Beteiligten und Wissenstransfer eine sehr wesentliche Rolle spielt. - Frage: „Wie groß ist ein Data Science Team im Durchschnitt und ist dieses Team nur damit beschäftigt?“
Antwort: Die Antwort auf diese Frage hängt wesentlich davon ab, wie viele Projekte parallel durchgeführt werden sollen. Kleine Explorationsprojekte und Proof-of-Concepts können vom Aufwand her auch von einer oder einem Data Scientist* durchgeführt werden, wenn diese Person in ein entsprechendes Projektteam eingebettet ist und über die notwendigen Kompetenzen verfügt, dieses Projektteam zu leiten. Dafür braucht es allerdings einen oder eine sehr erfahrenen Data Scientist*in, und auch in diesem Fall hilft es, wenn die Ideen, die während der Exploration entstehen, mit einer zweiten datenaffinen Person diskutiert werden können.
Bei der Produktionalisierung kann ein*e Data Scientist*in bzw. Data Engineer*in genügen, wenn das Projekt entsprechend einfach umzusetzen ist. Je nach architektonischen Anforderungen und Aufwand gibt es hier allerdings Spielraum nach oben.
Wenn man am Beginn der Reise steht, also seine ersten AI Projekte plant und durchführt, können bestehende Mitarbeiter*innen auch noch nicht Vollzeit am Data Science Projekt mitarbeiten. Es ist allerdings sehr zu empfehlen, dass genügend Zeit reserviert wird, sonst wird der Fortschritt nicht den Erwartungen entsprechen. In jedem Fall ist es sinnvoll, im Falle einer Umschulung bestehender Mitarbeiter*innen in Richtung AI einen oder eine erfahrene Data Scientist*in beizustellen, sei es in Form von externer Unterstützung oder durch die Anstellung einer entsprechenden Ressource im eigenen Unternehmen. - Frage: „Am Anfang haben Sie erwähnt, dass es ein Problem ist, die Daten ohne Zweck zu speichern. Ist es nicht noch schlimmer, wenn man die Daten gar nicht hat?“
Antwort: Das ist wohl wahr. In einer perfekten Welt (also im AI Wunderland, das im Vortrag erwähnt wurde), sind die Daten zu einem bestimmten Zweck gesammelt worden, was zur Folge hat, dass es jemanden gibt, dem die Daten ein Anliegen sind, der sich um die Daten kümmert und für eine entsprechende Datenqualität sorgt.
Falls es noch gar keine Daten zu einem Sachverhalt gibt, dann verunmöglicht das natürlich die Durchführung eines AI Projektes zu diesem Business Case. Das kann ein Worst-Case-Szenario sein, wenn es lediglich um das Projekt selbst geht, oder aber es kann ein Anlass sein, zu planen wie die Daten gespeichert werden sollen und welche Fragen man dann mit den Daten beantworten können will. Insofern stellt es auch eine Chance dar, deren Potential dann längerfristig genutzt werden kann. - Frage: „Wieviel % der Arbeitszeit muss ein Data Owner (Kunde) für ein AI Projekt zur Verfügung stellen (neben dem Daily-Business)“
Antwort: Der oder die Data Owner*in muss genügend Zeit und Ressourcen haben, Fragen zu den im Projekt verwendeten Daten zu beantworten. Zu Beginn eines Explorationsprojektes oder Proof-of-Concepts, wo es um Datenexploration und Datenaufbereitung geht, wird es hier vermutlich mehr Klärungsbedarf geben, da die Datenquelle dem oder der Data Scientist*in noch nicht bekannt ist. Im Rahmen des IT-PS Projektmodells finden wöchentliche Status-Meetings statt, die meist zwei bis drei Stunden dauern. In diesen Meetings werden inhaltlich wichtige Details zu den Daten und den verwendeten Algorithmen besprochen, und es wird bestimmt, in welche Richtung weitergearbeitet wird. Zumindest diese Zeit sollte der oder die Data Owner*in zur Verfügung haben, denn es ist wichtig, dass alle involvierten Personen bei diesen Status Meetings dabei sind. In den ersten Wochen kann es darüber hinaus von Vorteil sein, wenn ein paar Stunden mehr Zeit auf Seiten des oder der Data Owners* eingeplant wird, da es in den frühen Explorationsphasen oft zusätzliche Fragen zu den Daten gibt. - Frage; „Sie sagen die Geschäftsführung braucht ein “Grundverständnis von AI”. Was bedeutet das?“
Antwort: Ein Grundverständnis von AI im Management ist wichtig, damit keine unrealistischen Erwartungen entstehen, weder im Management selbst noch bei den Mitarbeiter*innen. Grundverständnis hat nichts damit zu tun, dass man die mathematischen Grundlagen von AI verstehen muss, das ist absolut nicht notwendig. Es geht darum, ein Gefühl zu entwickeln, was mit Daten und AI möglich ist und was nicht. Um dieses Gefühl zu entwickeln, braucht es einerseits ein gewisses Basiswissen, und andererseits Erfahrung durch reale Projekte.
Das Basiswissen versuchen wir im Tages-Workshop “Strategie-Workshop Data & AI”, den wir mit unserem Partner mosaiic GmbH entwickelt haben, zu vermitteln. Es kann aber auch aus anderen Quellen kommen, wenn man sich eingehender mit dem Thema beschäftigen will.
Die Entwicklung von Erfahrung im Bereich von AI ist am Anfang natürlich ein Henne-Ei-Problem: Man braucht eine gewisse Erfahrung, um AI Projekte leichter durchführen zu können, allerdings bekommt man diese Erfahrung hauptsächlich eben durch die Durchführung von AI Projekten. Hier versuchen wir mit unserem IT-PS Projektmodell, alle Stakeholder (also auch das Management) möglichst gut ins Projekt einzubinden, damit diese Erfahrung schnell und einfach gesammelt werden kann.
Fragen an Rainer Kegel
- Frage: „Wie funktioniert die Zusammenarbeit mit den verschiedenen Fachbereichen?“
Antwort: Analog wie in Projekten, der Data Owner (product owner) muss als Teil des Teams immer dabei sein! - Frage: „Ist der data owner typischer Weise aus dem Kernteam oder aus den Kompetenzen KUs ?“
Antwort: Der Data Owner ist immer aus dem Fachbereich, das kann aber ein klassischer FachbereichsmitarbeiterIn sein, oder ein dort ansässiger Data Scientist! - Frage: „Wie gehen Sie mit dem Wert von Daten um? Ist der Wert der Daten allen bewusst? Sind Daten bei Ihnen wie vom Vorredner erwähnt auch irgendwie Katalogisiert?“
Antwort: Wir sind dabei die Metadaten zu katalogisieren, der Wert von Daten größtenteils aber nicht flächendeckend bewusst. Das ist ein langwieriger Prozess bei derart großen Unternehmen! Wichtig ist aber, dass das Analytics Competence Center den Wert von Daten erkennt/kennt, dann können sie die Fachbereiche in diese Richtung beraten! - Frage: „ @Ethische Zertifizierung – Wie weist man “keinen Bias” nach?“
Antwort: Dazu müssten Sie mit unseren Experten sprechen, das ist Teil der Zertifizierung. Gerne kann ich diesen Austausch organisieren! - Frage: “War die Matrixorganisation von Anfang an so geplant oder hat sie sich entwickelt?“
Antwort: War von Anfang an so geplant, viel Wissen liegt dabei beim Fachbereich, daher war eine Ansiedlung eben dort auch sinnvoll! Wobei die Analytics Competence Center Steuerung aus der Konzernleitung erfolgt! - Frage: „Können Sie etwas zu den messbaren Ergebnissen (Kosteneinsparung, Umsatzsteigerung) der Initiativen sagen (im vgl. zum Aufwand)? Grüße Tobias“
Antwort: Das ist unterschiedlich je nach Use Case. Manche Anwendungsfälle haben auf den ersten Blick einen riesigen Mehrwert, der dann nicht gehoben werden kann; diese Use Cases nehmen dann den „Power Point Exit“. Andere Use Cases haben auf den ersten Blick wenig Mehrwert und entpuppen sich dann als Top Fälle. Hier muss zumindest bis zum zweiten/dritten Gate gewartet werden, ansonsten wirft man ein tolles Thema zu früh weg. Der EMAIL Kategorisierungs Use Case war im Prototyp ein Aufwand von 14 PT für unseren Chef Data Scientist! Operationalisierung noch ein halbes Jahr. Mehrwert überschlagen bei 2 Mio. über 5 Jahre! - Frage: „Wie treffen Sie “make or buy” Entscheidungen? Lösen Sie alle Use Cases intern im Data Science Team?“
Antwort: Ja! Da haben wir das Glück, dass wir schon viel Wissen im Konzern haben. Einzelne Spezialthemen lösen wir aber mit externen Unternehmen, vor allem wenn es dort schon ausgewiesene Expertise gibt. - Frage: „Wie betrachten bzw. beurteilen Sie den Beitrag zur Wertschöpfung im Geschäftsfall durch KI? Gibt es hier ein repräsentatives Beispiel?“
Antwort: An sich wie bei allen anderen Use Cases. Eingesparter Aufwand in €, Prozessoptimierung in €, Qualitätsverbesserungen sofern die messbar sind,…..! Der EMAIL Kategorisierungs-UC war im Prototyp ein Aufwand von 14 PT für unseren Chef Data Scientist! Operationalisierung noch ein halbes Jahr. Externe Software für derartige Systeme etwa 500k inkl. Betrieb pro Jahr! Mehrwert überschlagen bei 2 Mio. über 5 Jahre! - Frage: „Wie groß ist das Analytics Competence Center an Personen? Wieviel Use Cases laufen im Schnitt? Wie lange ist die durchschnittliche Dauer eines UC’s?“
Antwort: Derzeit in etwa 40-50 Personen verteilt im Konzern! Die meisten Personen in den Unternehmen direkt im Fachbereich, von unseren eigenen Spezialisten ausgebildet. Die durchschnittliche Dauer von Use Case Umsetzungen kann ich nicht beantworten, Range geht hier von 1 Monat bis mehrere Jahre! Z.B. ein predictive maintenance Use case ist eigentlich nie abgeschlossen!
Fragen an Thomas Huber
Die Antworten von Thomas Huber, lesen Sie im nächsten Blogbeitrag
Sie haben Fragen zu Data Science? Kennen Sie schon unsere Data-Science Seite? Link
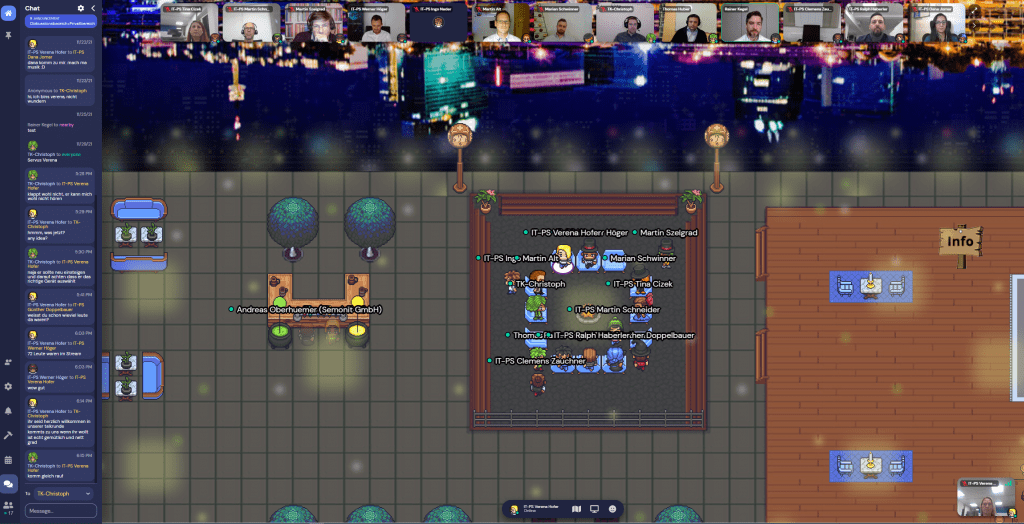
Online-Netzwerken mit gather.town
Trotz Corona-Situation war es uns wichtig den Austausch zwischen Gästen und Vortragenden zu ermöglichen. Aus eigener Erfahrung wissen wir, dass Onlinemeetings aber mittlerweile keinen Reiz mehr haben. Also haben wir eine andere Möglichkeit gesucht; und mit gathertown gefunden. Bei weiterer Recherche sind wir auf das Startup Unternehmen teamkiste gestoßen. Dieses Team hat uns innerhalb kürzester Zeit eine eigene virtuelle IT-PS Lounge aufgesetzt mit Rooftopbar, einem Funcorner und vielen verschiedenen Möglichkeiten und Räumen. Sogar ein Christbaum war dabei. Die Avatare und angebotenen Spiele wie Flipper und Supermario im Funbereich haben viele Gäste in Jugenderinnerungen schwelgen lassen. Teamkiste ist übrigens ein Projekt von zwei Brüdern aus dem Mostviertel in Niederösterreich.
Lesen Sie weiter in unserem nächsten Blogbeitrag zum Data Science Talk 2021: Behind the Scenes




